Despite the language’s simplicity and declarative nature, SQL can be surprisingly opaque for developers. SQL successfully hides many details related to the reading & writing of data on disk, making it fairly intuitive for most tasks.
But when performance is a concern and you need to understand what decisions the SQL query planner is making for you based on a given query, a lower-level understanding of the database can provide clarity.
Indexes are a good example of this; from the outset I knew that adding indexes could improve performance, but had no idea why they made a difference or how they were actually used.
This is where some knowledge of data structures comes in handy: a database index is a combination of a balanced tree and a doubly-linked list.
These concepts are better expressed visually:
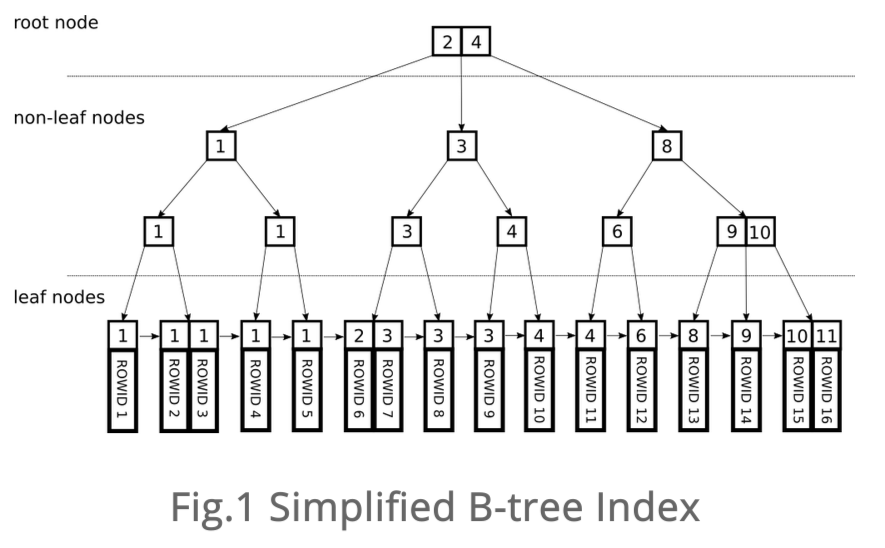
The leaf nodes contain either the actual data itself (clustered index) or references to the actual rows (nonclustered index).
Because the tree is height-balanced, this allows for very fast O(log n) searches across all of the leaf nodes at the bottom. And because these nodes are doubly-linked, it makes insertions much less expensive - only the neighboring nodes are affected on a given insert.
But it’s important to keep in mind that this tree must be kept in-balance; so as new records get added to the database, indexes must be updated accordingly. This is why you have to be careful: besides consuming more disk space, adding too many indexes can cause inserts to become slower, as each one will require updates to the table’s indexes.
So if you have a table column that experiences frequent inserts, it may be better to limit the number of indexes using that column. Conversely, if it experiences a lot of reads but is rarely written to, then you may want to prioritize fast searches by adding more indexes.
I’m still learning, so take the above explanations with a grain of salt. Ultimately I would refer to this great resource for more information on SQL indexing: https://use-the-index-luke.com/